{kind=link}
{kind=link}
The BERT base model embeds each token into 768 dimensions. Therefore it would be very expensive to embed all words exist in English or other languages. BERT gets around this problem by keeping some popular words, but break other words into pieces known as word pieces or sentence pieces . The BERT base model for English uses about 30K of words pieces.
What are these word pieces, and how their embeddings look like? While the prebuilt BERT model such as those in Tensorflow-hub has an embedding for each word pieces, visualize these directly is not very meaningful, since these are not used directly for downstream classification tasks. Instead, when you feed a sentence like
enjoying the wonderfulness
through the BERT model, it is broken down into 6 pieces:
'[CLS]', 'enjoy', 'the', 'wonderful', '##ness', '[SEP]'
and BERT will produce a 768-dimensional embedding for each of these 6 pieces. The pooled embeddings of these, or just the embedding of '[cls]', encapsulate the meaning of the input sentence.
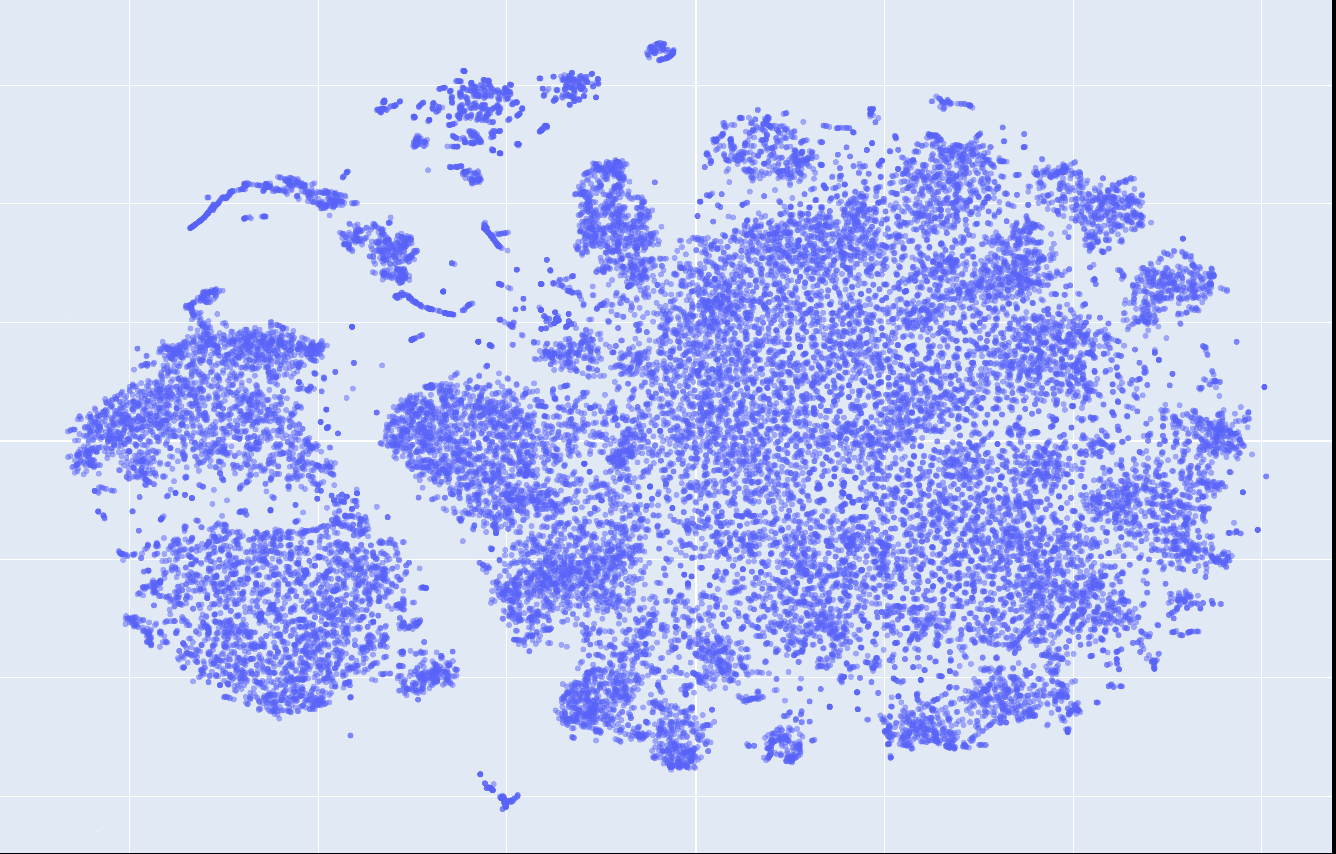
So to understand the 30K word pieces, we pass each of these through the BERT model, and take the '[cls]' embeddings as the embeddings for for the word piece. Since the embedding is of 768 dimension, we project to 2D via TSNE.
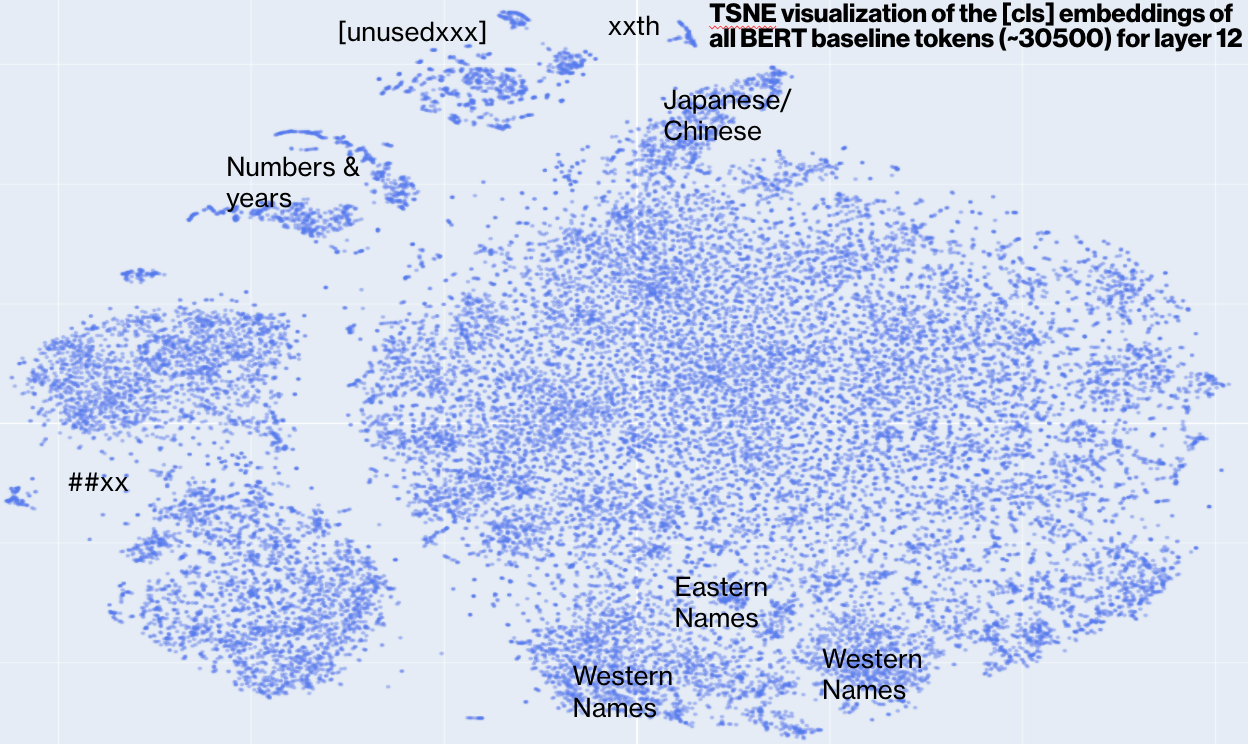
Here is what it looks like overall
We can see more details using the svg file or this version (which uses overlap removal algorithm in Graphviz to get rid of text overlaps)
Here are some highlights. This area has many names

This region has many math terms

This region has many place names:

This region has many adverb/adjectives:

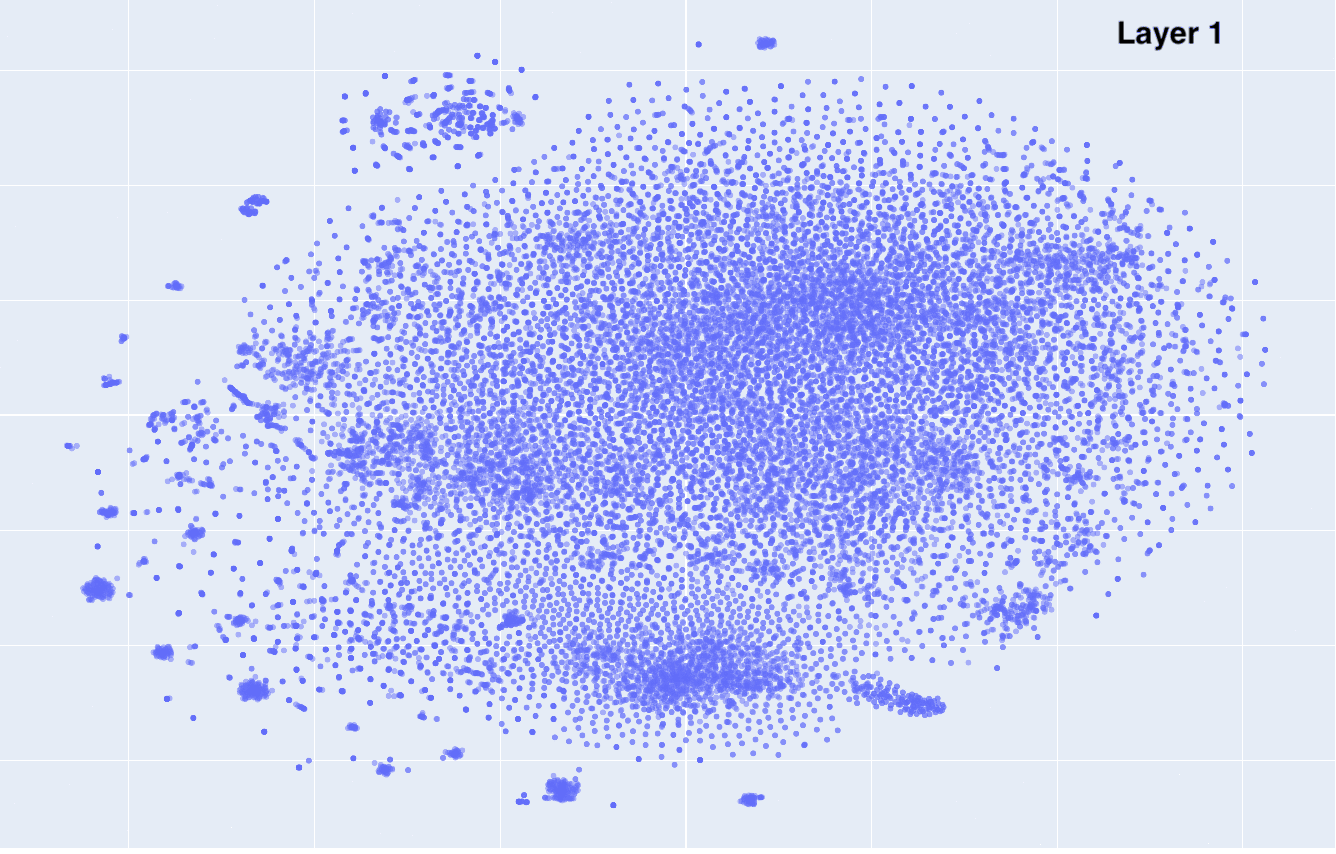
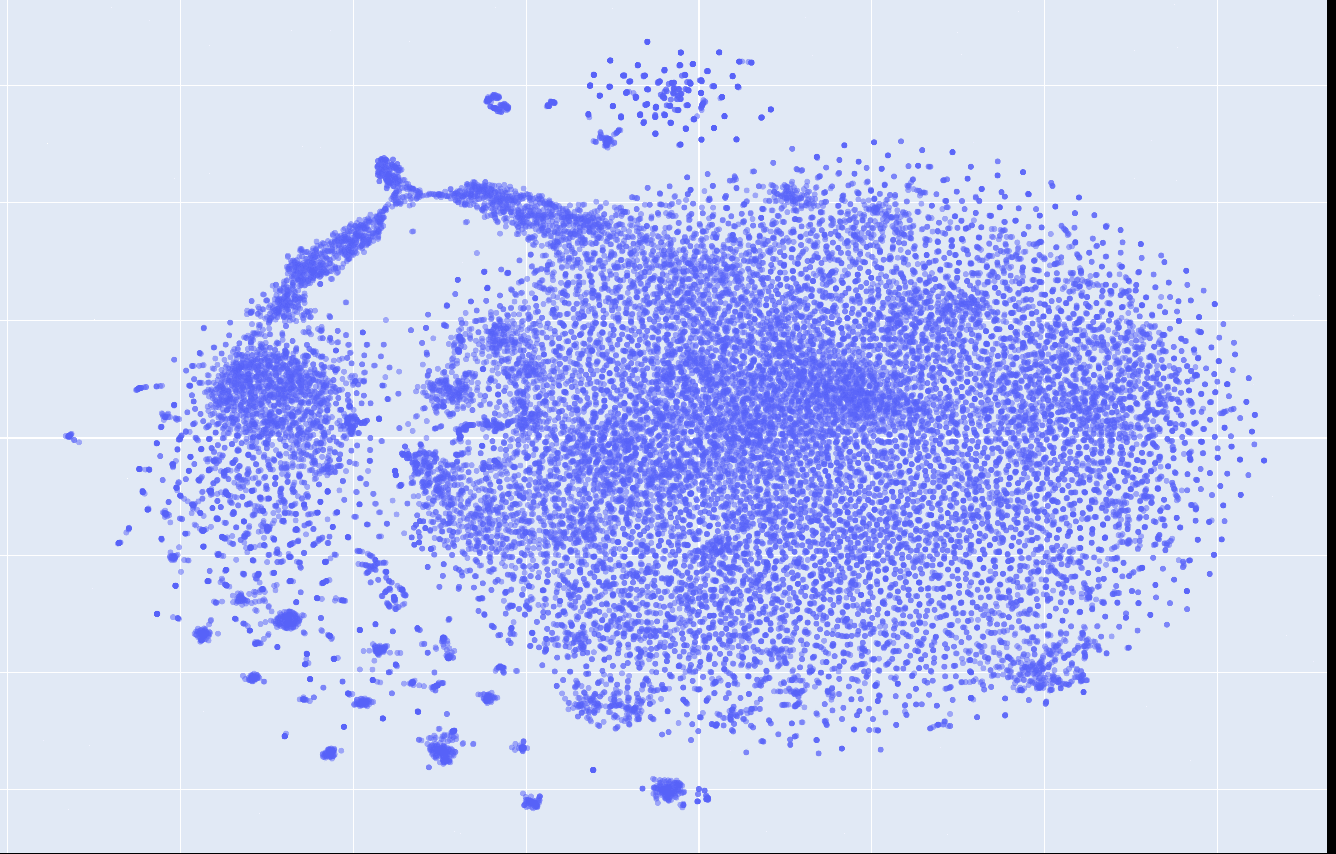
This is what the embeddings look like from layer 1 to 12. Click on each to see an interactive version.
 |
 |
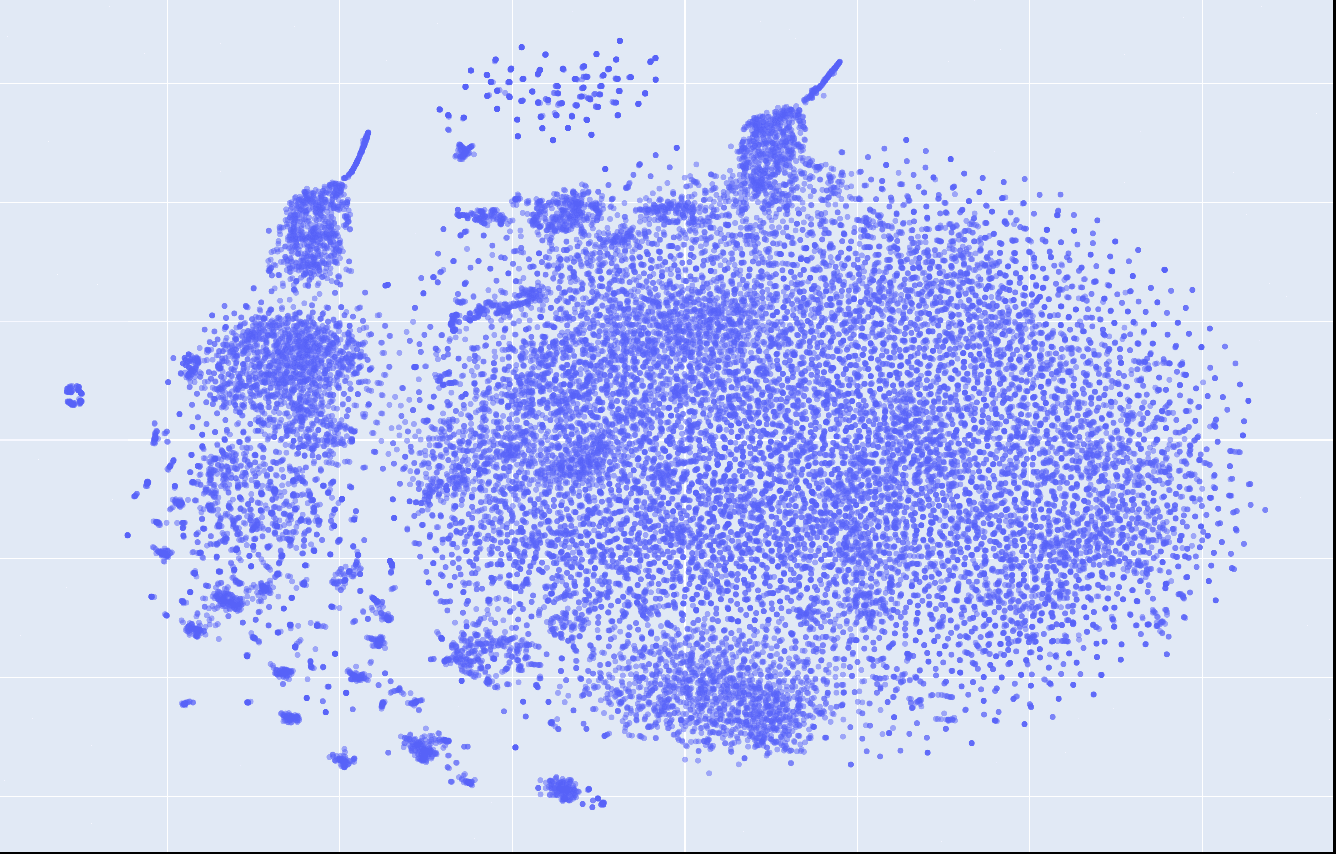 |
| layer 1 | layer 2 | layer 3 |
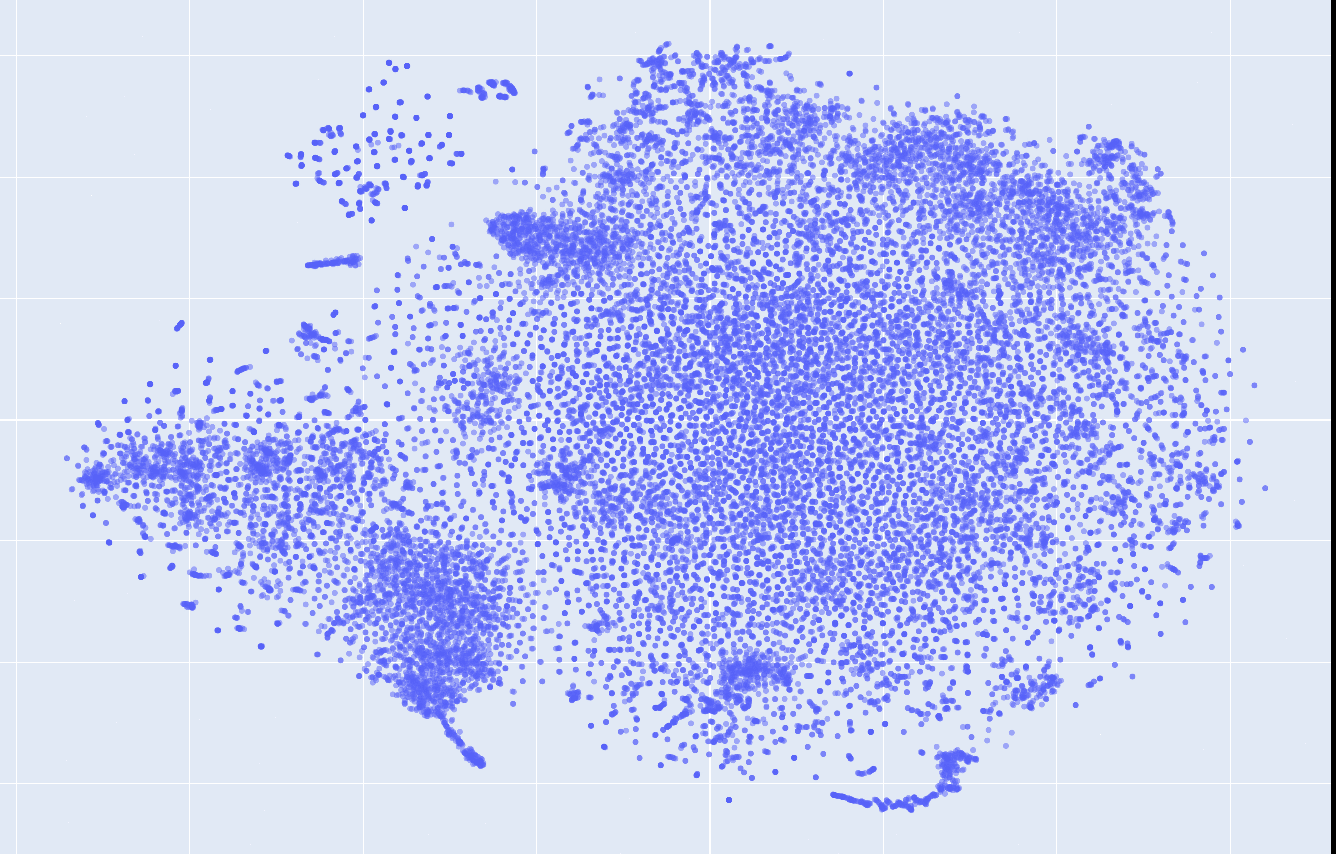 |
 |
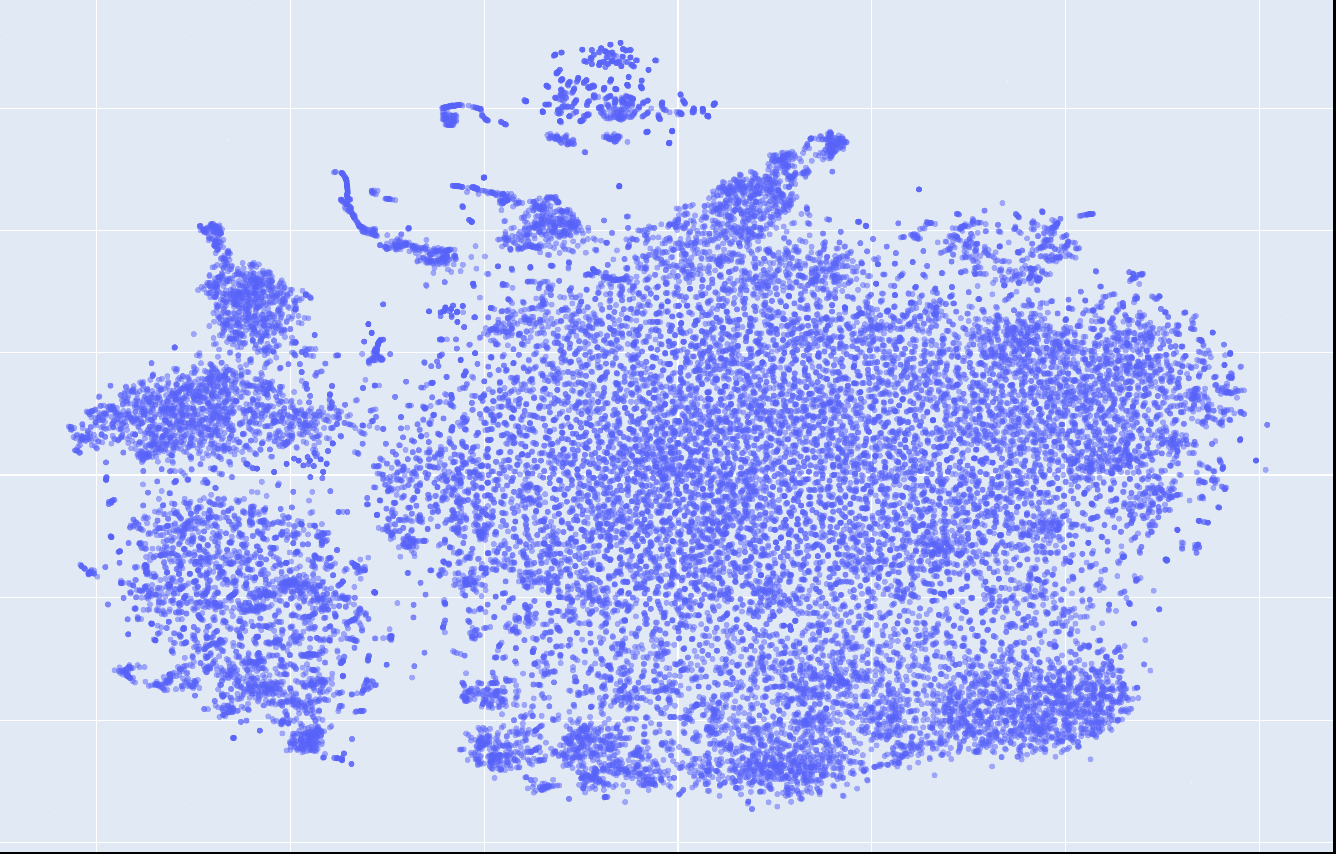 |
| layer 4 | layer 5 | layer 6 |
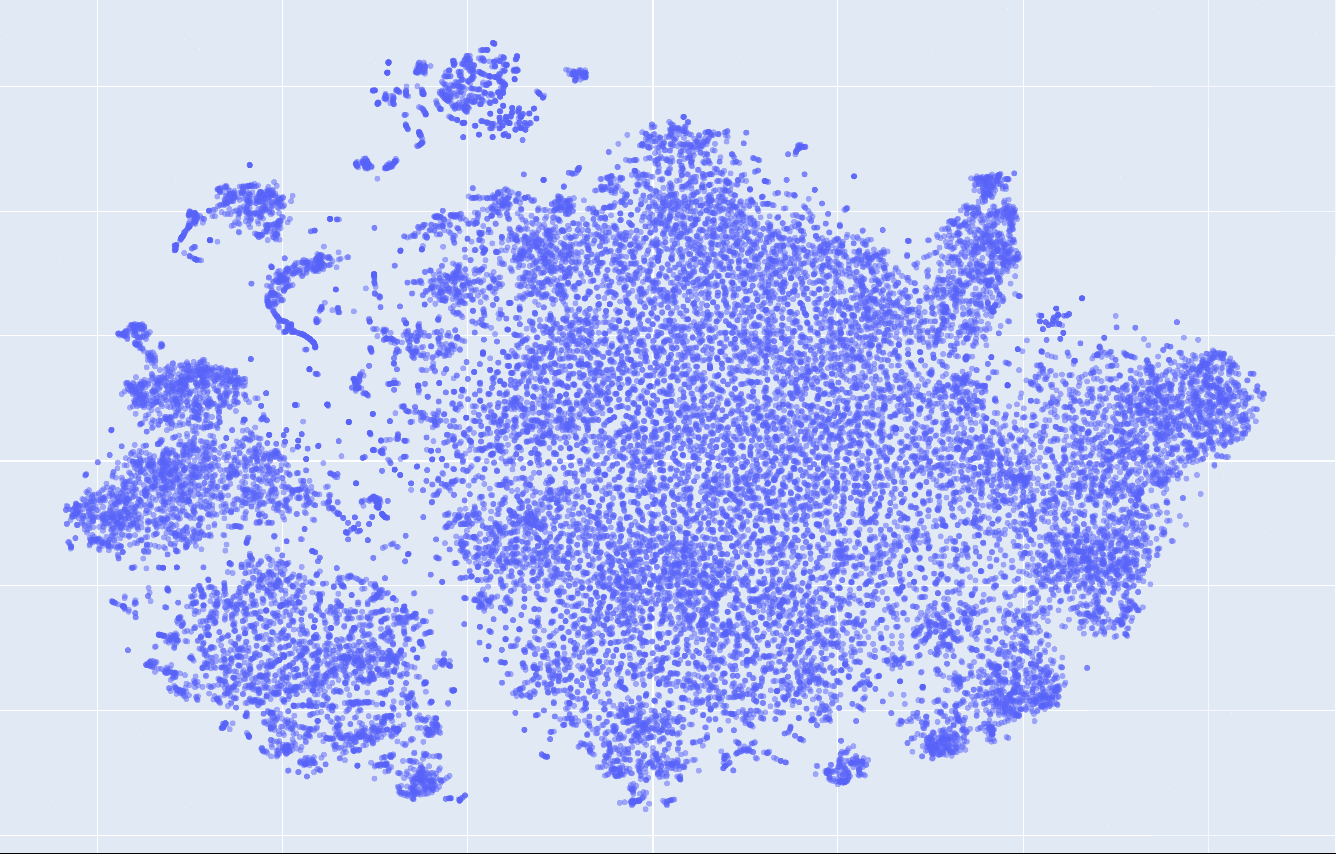 |
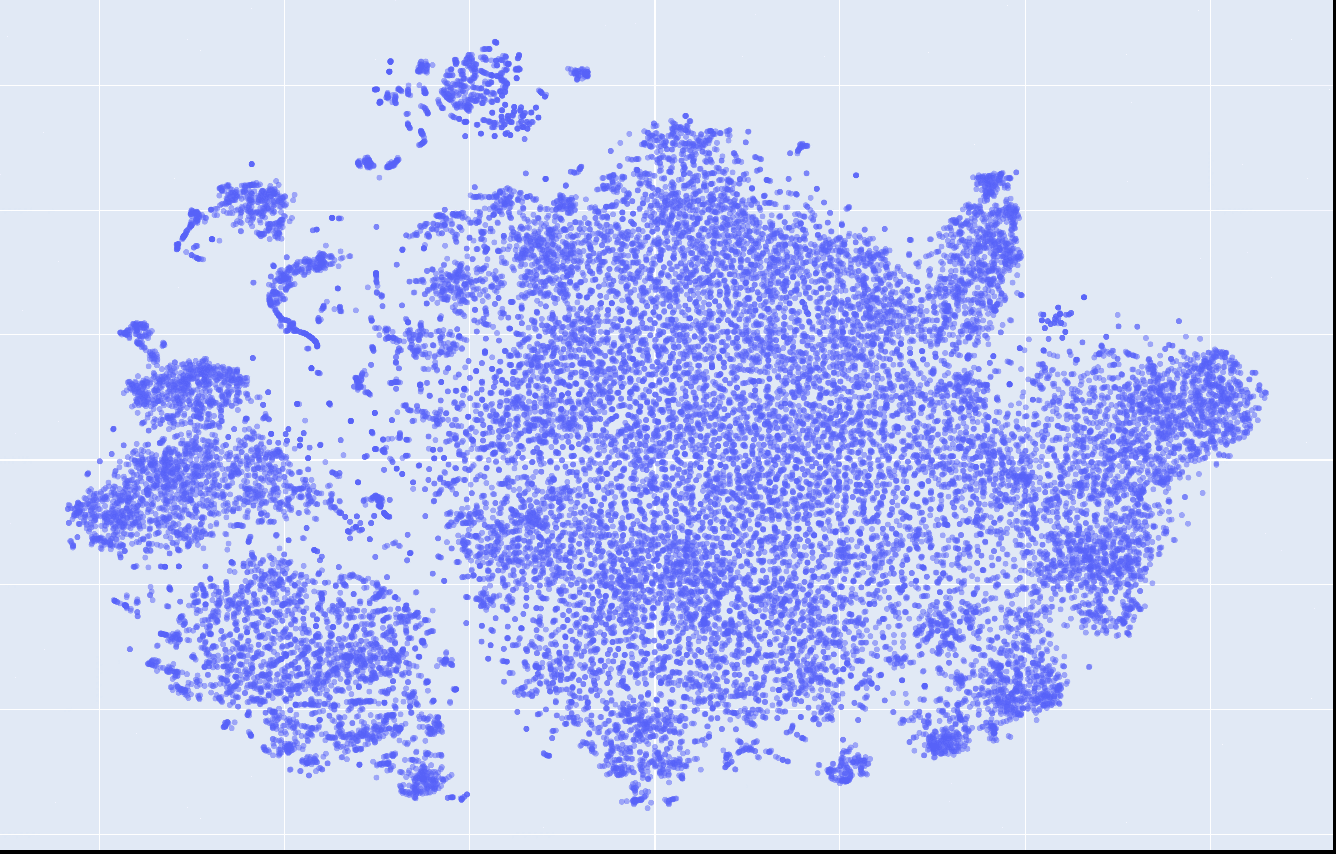 |
 |
| layer 7 | layer 8 | layer 9 |
 |
 |
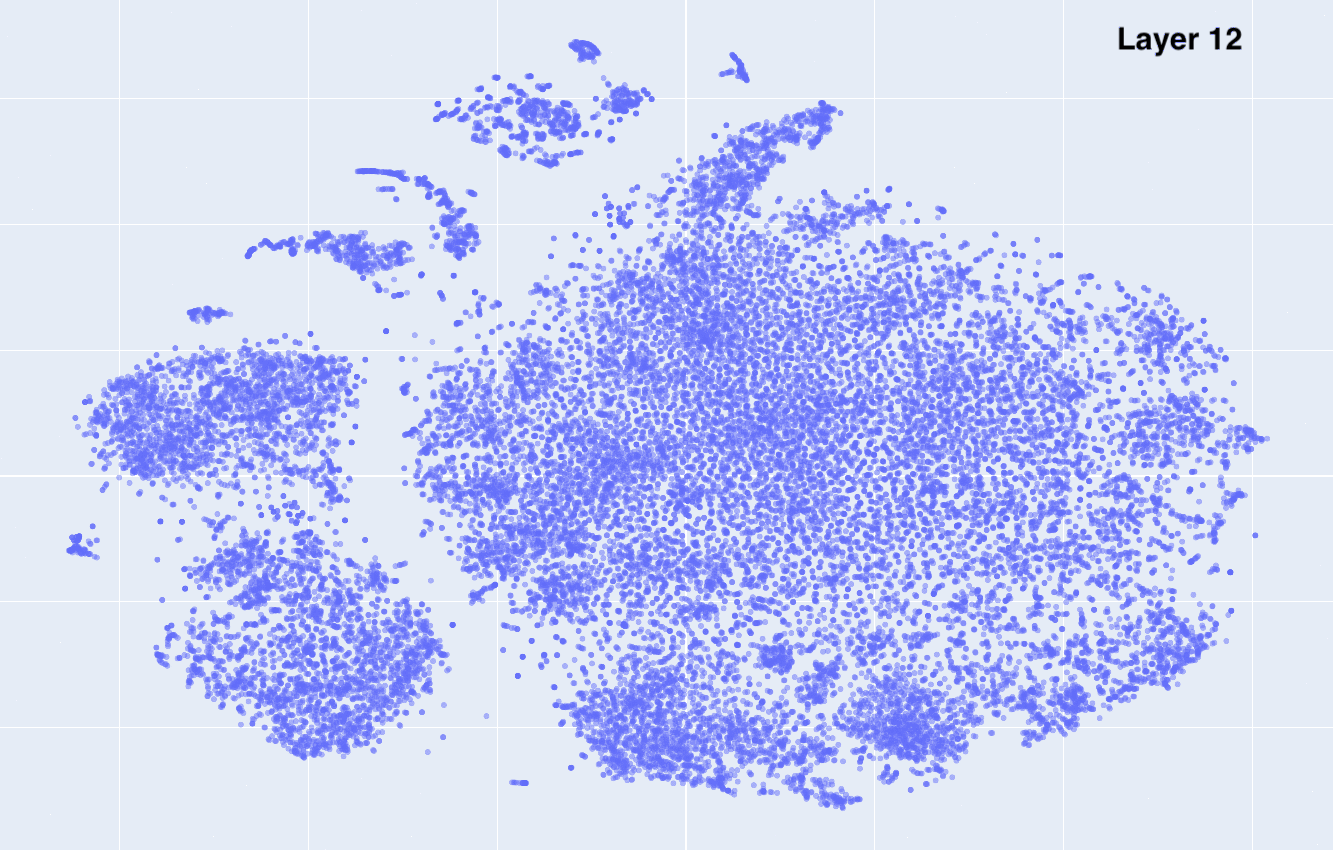 |
| layer 10 | layer 11 | layer 12 |