We all have the experience that by looking at the name of a person, we can guess a lot of information about the person with regard to the gender and ethnicity. In our earlier work, we found that name embeddings can be used features for gender, ethnicity and nationality classification.
In this work, we argue that the gender information is encoded in the spelling of the names.
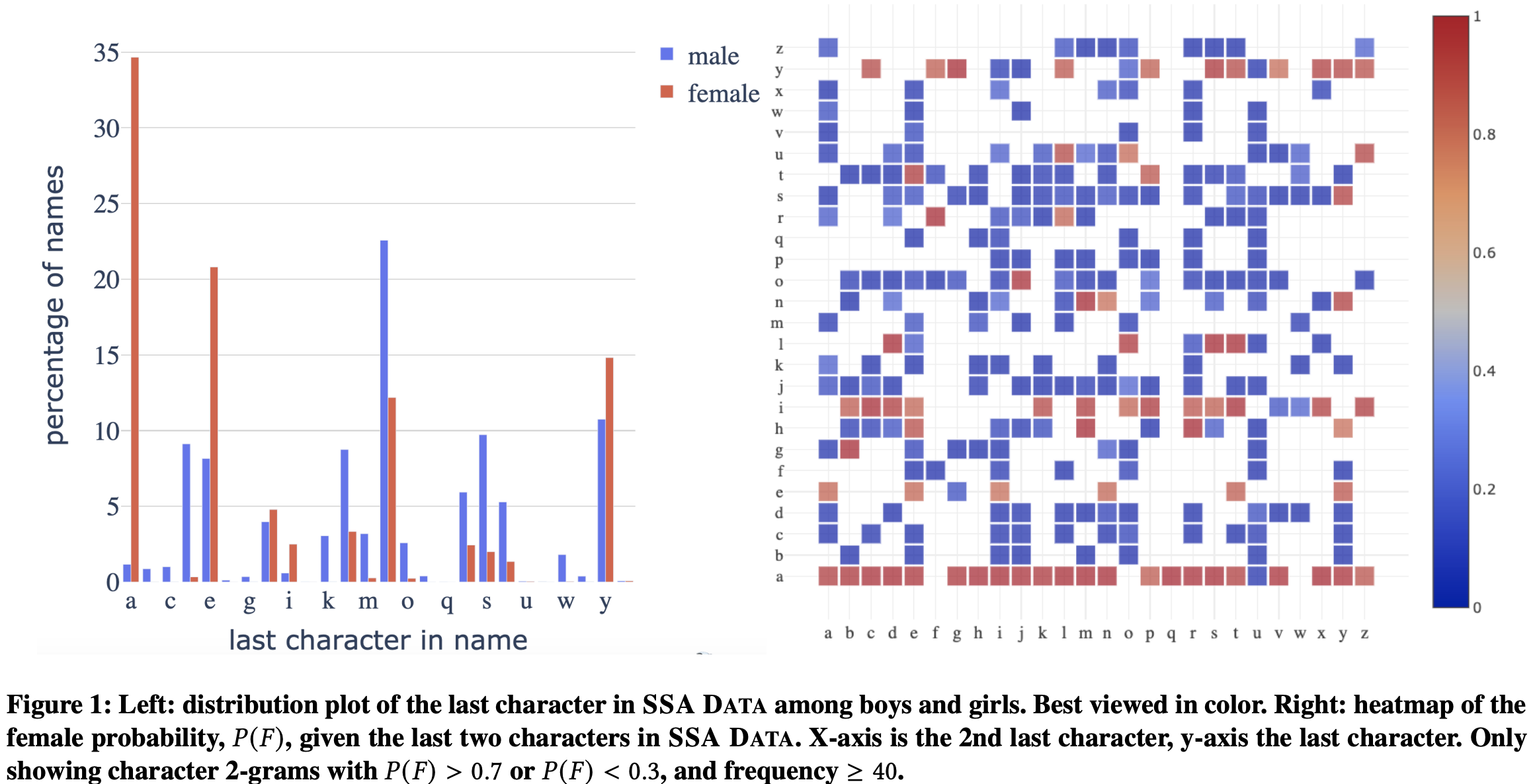
For example, if someone's name end with "a", very likely that person is female (left side of the following figure). However, if the second last character is "u", that person is likely a male (think of "Joshua", see the blue square in the bottom row of the right side of the figure).
We proposed a number of character based ML models which shows great performance. Models trained on large Yahoo data also extends well to data from the Social Security Admin (Table below).
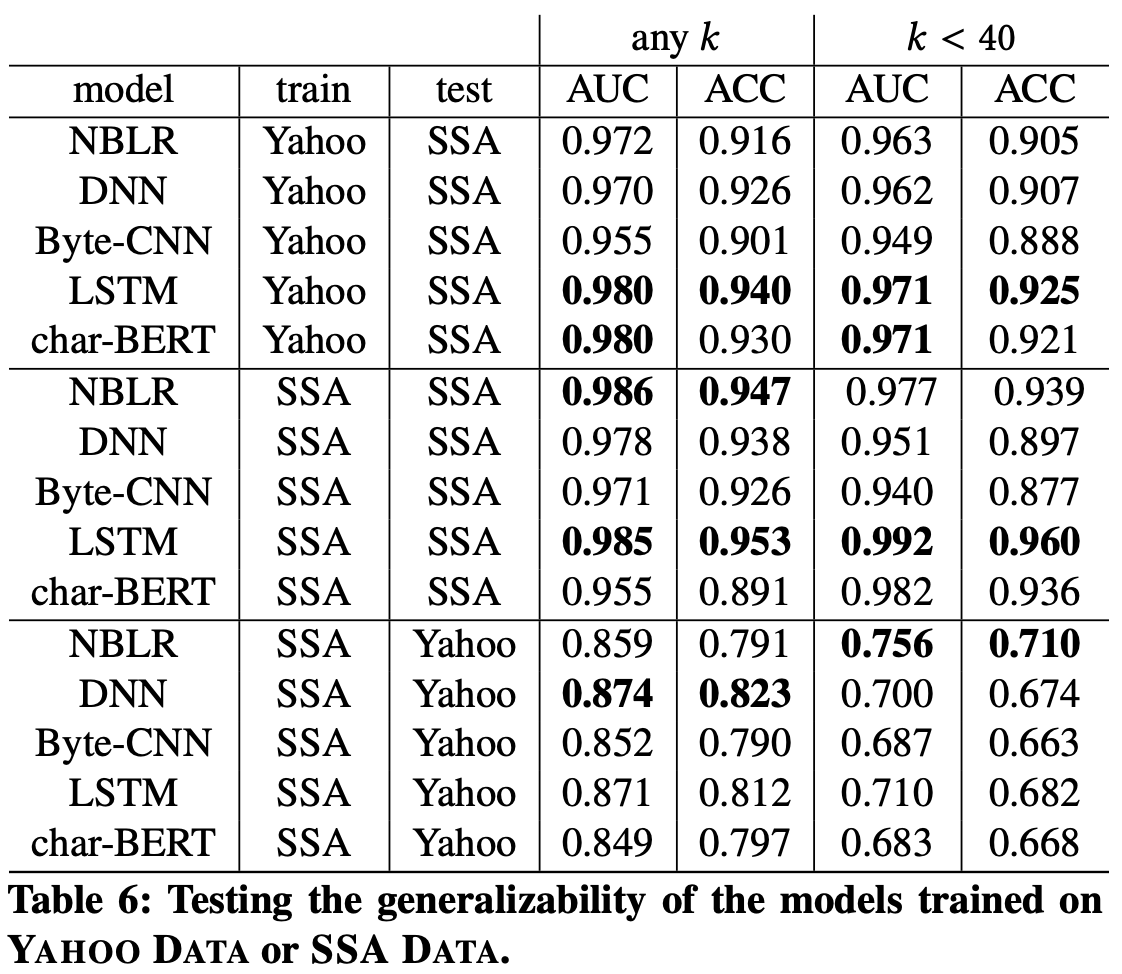
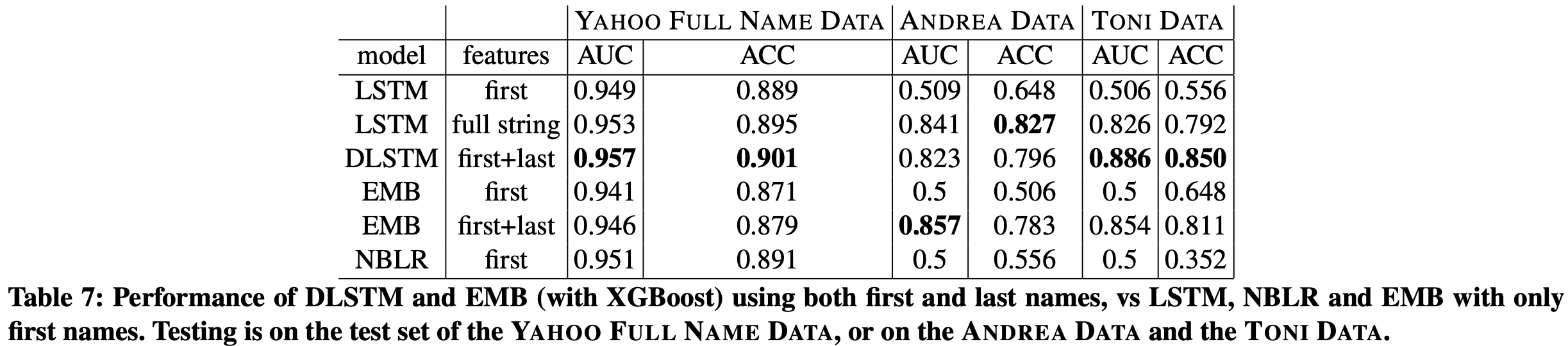
While the gender is typically conveyed in the first name, there are cases when the same first name can be used for one gender in one culture, but another in a different culture. For example, the Italian male name "Andrea" (derived from the Greek "Andreas") is considered a female name in many languages, such as English, German, Hungarian, Czech, and Spanish. We found that combining the first name with the last name as features and a dual-LSTM architecturem, the performance is better than using first name alone, because this set up help to disambiguate situations such as "Andrea".
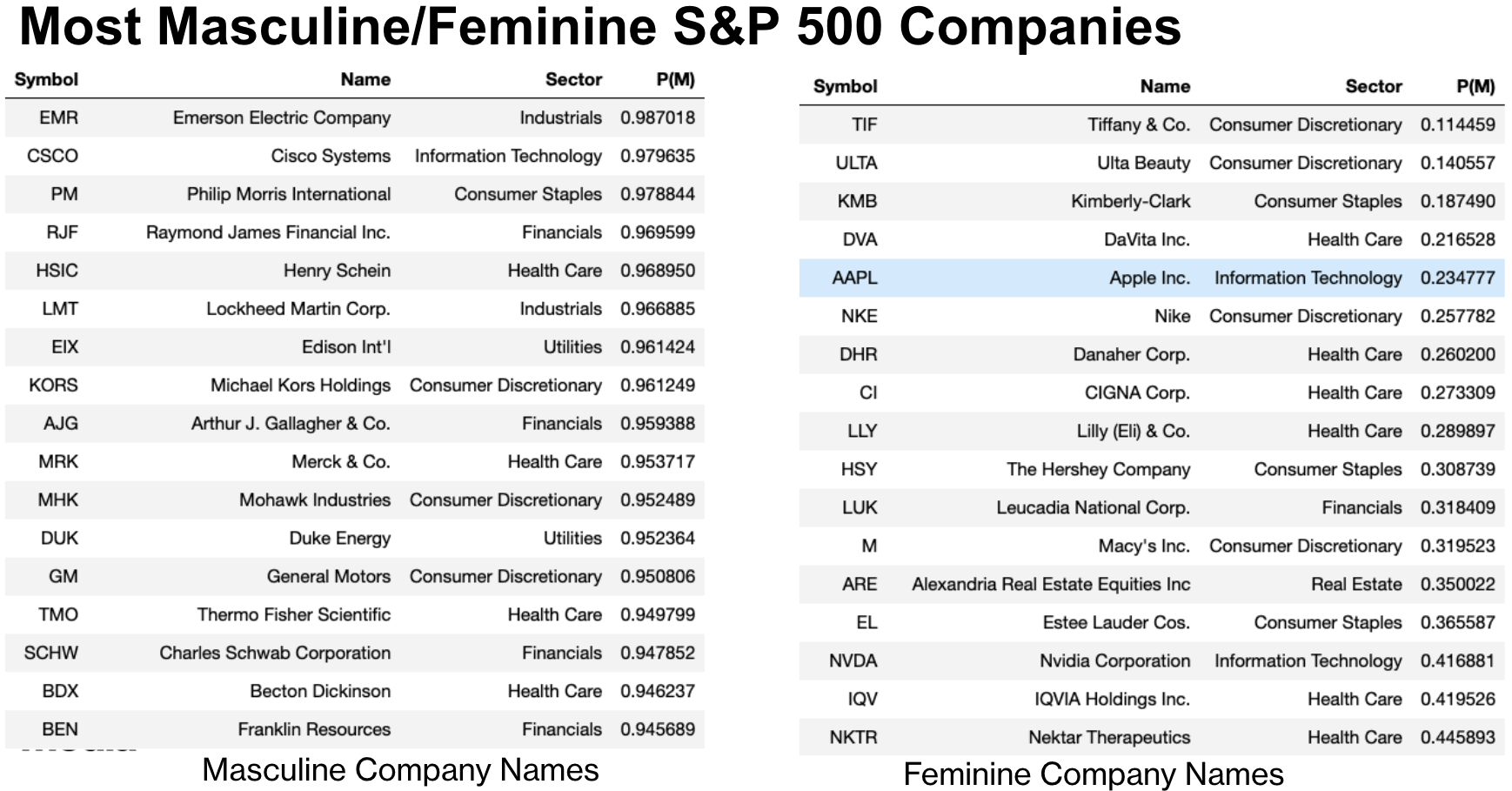
Since the character-based models can be applied to any string, we can find the most masculine and feminine names in S&P 500 companies (Table below). It is interesting to see that many "masculine" named companies are in engineering, while among the "feminine" named companies, there are many fashion and beauty production companies.
Reference: Yifan Hu, Changwei Hu, Thanh Tran, Tejaswi Kasturi, Elizabeth Joseph, Matt Gillingham, What's in a Name? -- Gender Classification of Names with Character Based Machine Learning Models, to appear in the journal of Data Mining and Knowledge Discovery, 2021.