As mentioned before, the solution of the system of linear equations (9) is not unique. The motivation of the algorithm [43], called the method of potentials here for reasons explained later, is to choose amongst these solutions one that minimizes the data movement. For this section (Section 4.3.4), the processor graph is assumed to be directed, with the direction of each edge going from the vertex with higher index to the one with lower index.
Let ![]() be the matrix associated with the linear system
(9), let
be the matrix associated with the linear system
(9), let ![]() be the vector of
be the vector of
![]() 's and
's and ![]() the right hand side of (9).
Assuming that
the Euclidean norm of the data movement is used as a measure of data
movement, and that
the unit communication cost between any two processors
the right hand side of (9).
Assuming that
the Euclidean norm of the data movement is used as a measure of data
movement, and that
the unit communication cost between any two processors ![]() and
and ![]() is
is
![]() . Let
. Let ![]() denote the diagonal matrix of size
denote the diagonal matrix of size
![]() consisting of the
consisting of the ![]() , then one needs to
find a solution
, then one needs to
find a solution ![]() which solves the following minimization problem:
which solves the following minimization problem:
Here ![]() is the
is the ![]() matrix associated with system (9).
It is called the vertex-edge incident matrix [68,8] of the directed
processor graph,
given by
matrix associated with system (9).
It is called the vertex-edge incident matrix [68,8] of the directed
processor graph,
given by

Applying the necessary condition for the constrained optimization problem
(see [27]), after some algebraic manipulation, one
has
Thus the problem of finding an optimal load balancing schedule
is transformed to that of solving the linear equation
(14). Once the Lagrange multipliers are found, then the load transfer vector is ![]() .
.
For any graph, each row ![]() of the
matrix
of the
matrix ![]() only has two non-zeros,
only has two non-zeros, ![]() and
and ![]() , corresponding to the
head and tail vertices of the edge
, corresponding to the
head and tail vertices of the edge ![]() .
Therefore the amount of load to be transferred from processor
.
Therefore the amount of load to be transferred from processor ![]() to processor
to processor ![]() (assuming
(assuming ![]() is the head and
is the head and ![]() the tail), along the edge
the tail), along the edge ![]() ,
is simply
,
is simply
The matrix ![]() is a generalized form of the Laplacian matrix
(6).
For many parallel computers the unit communication cost
is roughly the same
between any two processors (
is a generalized form of the Laplacian matrix
(6).
For many parallel computers the unit communication cost
is roughly the same
between any two processors (![]() ),
in which case this matrix is the same as (6).
),
in which case this matrix is the same as (6).
The linear system (14) can be solved by many standard numerical algorithms. The conjugate gradient algorithm was used in [29] because it is simple, easy to parallelize and converges quickly. For preconditioning, the diagonal of the Laplacian may be used.
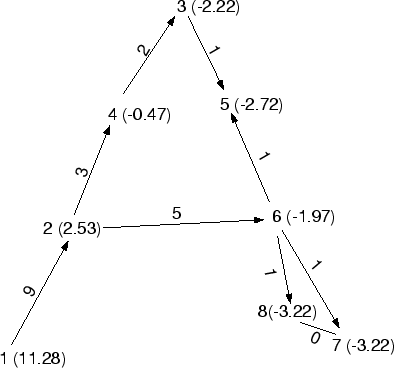
As a simple example, considering the processor graph in Figure 14.
The load for each processor is
given in brackets. The average load is 16.25 and the largest load imbalance is
![]() %.
The Laplacian system (assuming a weighting of
%.
The Laplacian system (assuming a weighting of ![]() ) is now
) is now
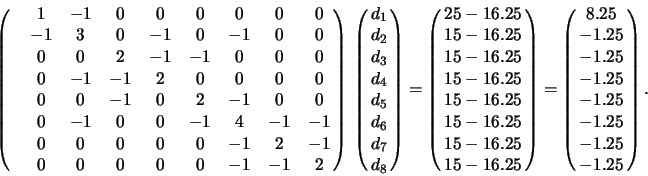
The solution of this linear equation is
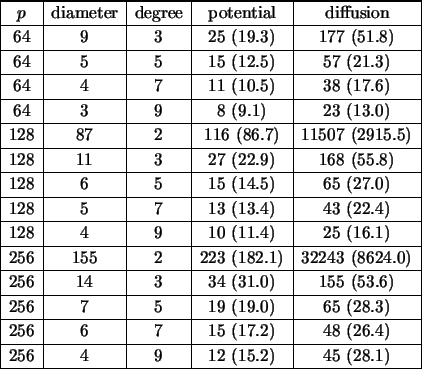
Table 2 gives the result of the method of potentials and that of the diffusion algorithm on random graphs of varying connectivity. The algorithms have been implemented on a Cray T3D with MPI. It can be seen that in general the method of potentials is faster, and that for graphs of small connectivity it is considerably faster. The same conclusion can be drawn when applying the two algorithms on processor graphs from real applications [43].
 |
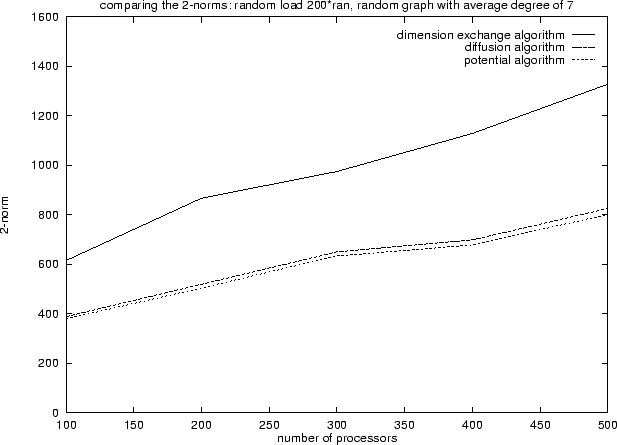 |
When
examining the Euclidean norm of migrating flow (Figure 16),
it was surprising to find that
the norm for the diffusion algorithm was usually as small
as that for the method of potentials, and much smaller
than that of algorithms such as the dimension exchange algorithm.
It has now been proved [44]
that diffusion type algorithms also have
a minimal norm property. In fact it is possible
to prove a rather general result [45] that
if a flow calculation
algorithm is based on the polynomial of the weighted Laplacian,
![]() where
where ![]() is a
is a ![]() -th order polynomial such that
-th order polynomial such that
![]() , then
the flow generated, provided that the
algorithm converges, solves (12).
In other words, all polynomial based flow calculation algorithms,
including the diffusion algorithm (11), generate
exactly the same minimal flow as the algorithm of potentials,
provided that the same edge weights
, then
the flow generated, provided that the
algorithm converges, solves (12).
In other words, all polynomial based flow calculation algorithms,
including the diffusion algorithm (11), generate
exactly the same minimal flow as the algorithm of potentials,
provided that the same edge weights ![]() 's are used.
In terms of the rate of convergence, the algorithm of potentials is
of course better.
It also converges for any positive edge weights.
's are used.
In terms of the rate of convergence, the algorithm of potentials is
of course better.
It also converges for any positive edge weights.